k8s部署meilisearch
给公司的公有云部署了一个,挺有意思的,我准备后续给我的博客也用上
官方文档:https://github.com/meilisearch/meilisearch-kubernetes
支持资源清单或helm部署
1
| wget https://raw.githubusercontent.com/meilisearch/meilisearch-kubernetes/refs/heads/main/manifests/meilisearch.yaml
|
几个注意点:
- 建议加上环境变量
MEILI_MASTER_KEY
- 调整
NodeSelector、taint
- 默认使用
emptyDir 作为 tmp 和 data 卷,生产肯定需要改成 pvc
1
| kubectl apply -f meilisearch.yaml
|
docker部署meilisearch
官方文档: https://www.meilisearch.com/docs/resources/self_hosting/getting_started/docker
1
2
3
4
5
6
7
| mkdir /meili_data
docker run -itd --name meilisearch \
-p 7700:7700 \
-v /meili_data:/meili_data \
-e MEILI_MASTER_KEY='MASTER_KEY'\
getmeili/meilisearch:latest
|
token暴露问题
部署完成后,我要求 iflow:
- 在我的博客顶端中间增加一个颜色素、线条细的搜索框
- 搜索框与 Meilisearch 进行关联,并通过 hexo 主题的配置文件
_config.yaml 配置
但完成后发现一个新问题,就是这样我发起搜索的请求中,会直接带有 master key,这肯定不行
有两种方法可以解决:
- 使用 master key 向 meilisearch 重新申请一个只有读权限的 key,然后展示这个 key
- 在 nginx 后端添加新的路由,并且附带 token 转发到本机的 7700 端口
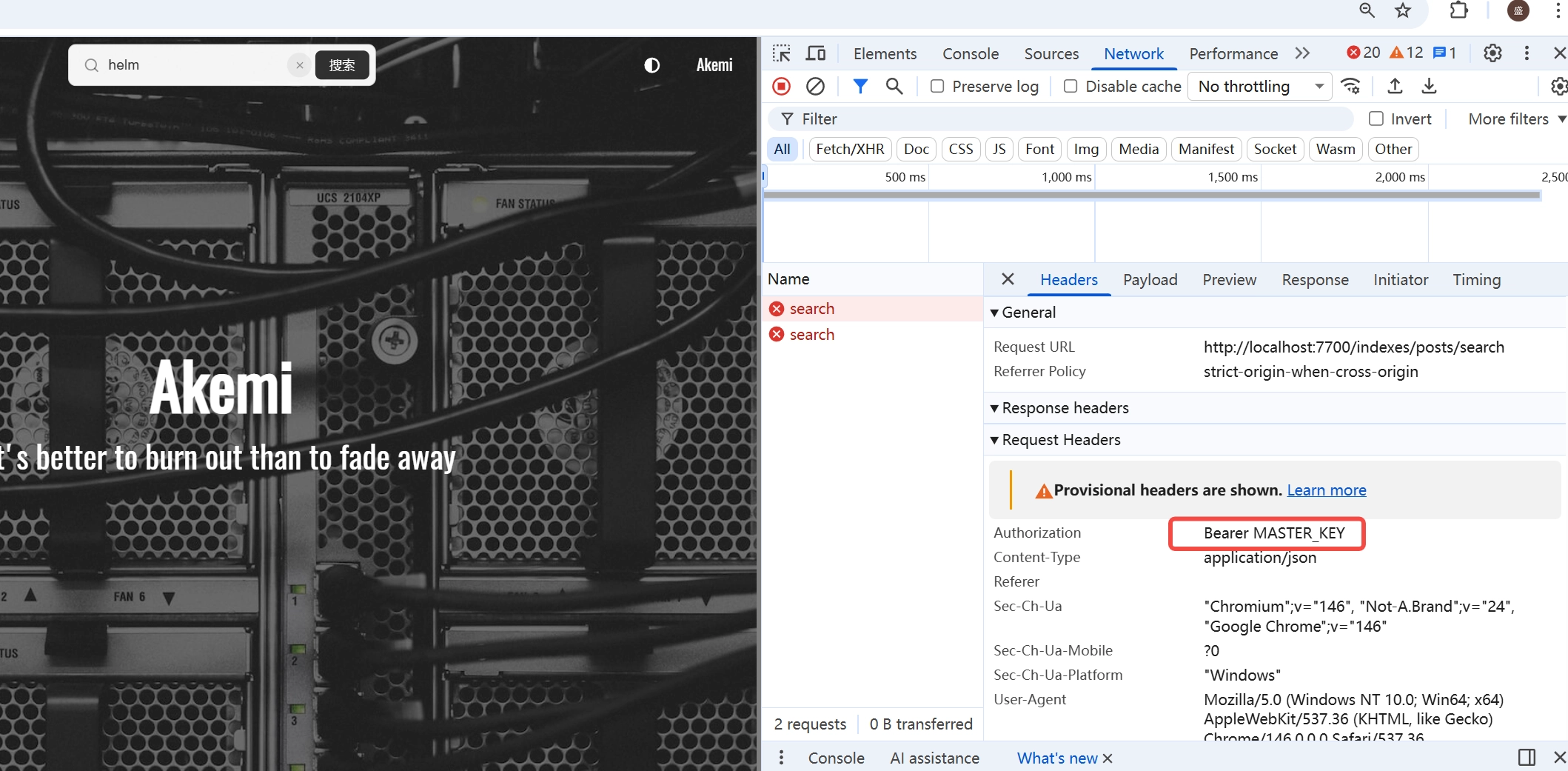
配置nginx
meilisearch 不使用 bearer auth,而是使用特殊请求头 X-MEILI-API-KEY(全大写)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
location /search/ {
proxy_pass http://127.0.0.1:7700/;
proxy_set_header X-MEILI-API-KEY "xxxxxx";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
if ($request_method != POST) {
return 405;
}
proxy_hide_header X-Meilisearch-Stats;
}
nginx -s reload
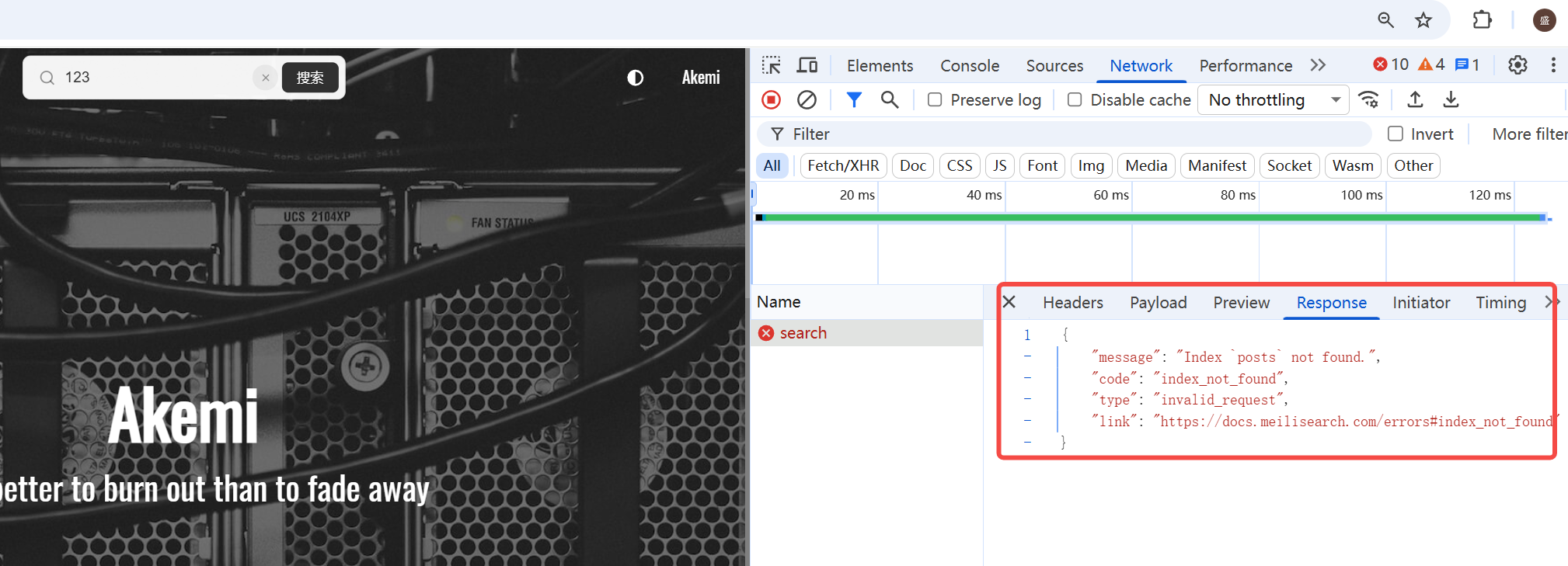
curl -X POST 'http://127.0.0.1:7700/indexes/posts/search' \
-H 'X-Meili-API-Key: xxxx' \
-H 'Content-Type: application/json' \
-d '{"q":"k8s","limit":5}'
{"message":"Index `posts` not found.","code":"index_not_found","type":"invalid_request","link":"https://docs.meilisearch.com/errors#index_not_found"}
|
创建索引与导入数据
这一步我让 openclaw 给我做了,主要内容如下:
中途我和它还对自动化、索引格式进行了讨论,所以说用 AI 还得懂技术才能用,不然他直接乱创建索引,查询效率就很低了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| 第一步:验证当前 Meilisearch 状态
curl -X GET 'http://114.55.64.10:7700/indexes' \
-H 'X-MEILI-API-KEY: xxxxx'
curl -X GET 'http://114.55.64.10:7700/indexes/posts' \
-H 'X-MEILI-API-KEY: xxxxx'
第二步:设计数据模型
基于 Hexo 文章结构:
{
"id": "唯一标识(如文件名哈希)",
"title": "文章标题",
"content": "文章纯文本内容",
"excerpt": "摘要",
"date": "发布日期",
"tags": ["标签数组"],
"categories": ["分类数组"],
"url": "文章URL"
}
第三步:创建/配置索引(如果需要)
curl -X POST 'http://114.55.64.10:7700/indexes' \
-H 'X-MEILI-API-KEY: xxxxx' \
-H 'Content-Type: application/json' \
-d '{
"uid": "posts",
"primaryKey": "id"
}'
第四步:提取 Hexo 博客文章
扫描 /blog/source/_posts/ 目录的所有 .md 文件
解析每篇文章:
- 提取 frontmatter(标题、日期、标签、分类)
- 提取内容并转换为纯文本
- 生成唯一ID
第五步:批量导入到 Meilisearch
curl -X POST 'http://114.55.64.10:7700/indexes/posts/documents' \
-H 'X-MEILI-API-KEY: xxxxx' \
-H 'Content-Type: application/json' \
-d '[{文章1数据}, {文章2数据}, ...]'
第七步:测试和验证
curl -X POST 'http://114.55.64.10:7700/indexes/posts/search' \
-H 'X-MEILI-API-KEY: xxxxx' \
-H 'Content-Type: application/json' \
-d '{
"q": "k8s",
"limit": 5,
"attributesToRetrieve": ["title", "date", "tags"],
"attributesToHighlight": ["title"]
}'
|
搜索框与下拉框问题
现在搜索框点了没反应,但在 F12 中可以看到接口已经返回了搜索到的文章。
这一步失败了很多次,所以重新创建了一个测试环境 /blog-staging,用 docker 运行 nodejs 环境,挂载我的 staging 环境,并暴露 4000 端口。让小龙虾直接改测试环境,我也可以通过 localhost:4000 做测试。
本文记录了使用 iflow 创建 MeiliSearch 搜索框的初步过程,包括部署、安全配置和索引创建。下一篇文章将详细介绍如何使用 OpenClaw 的三 Agent 协同工作流解决搜索功能的具体问题。
